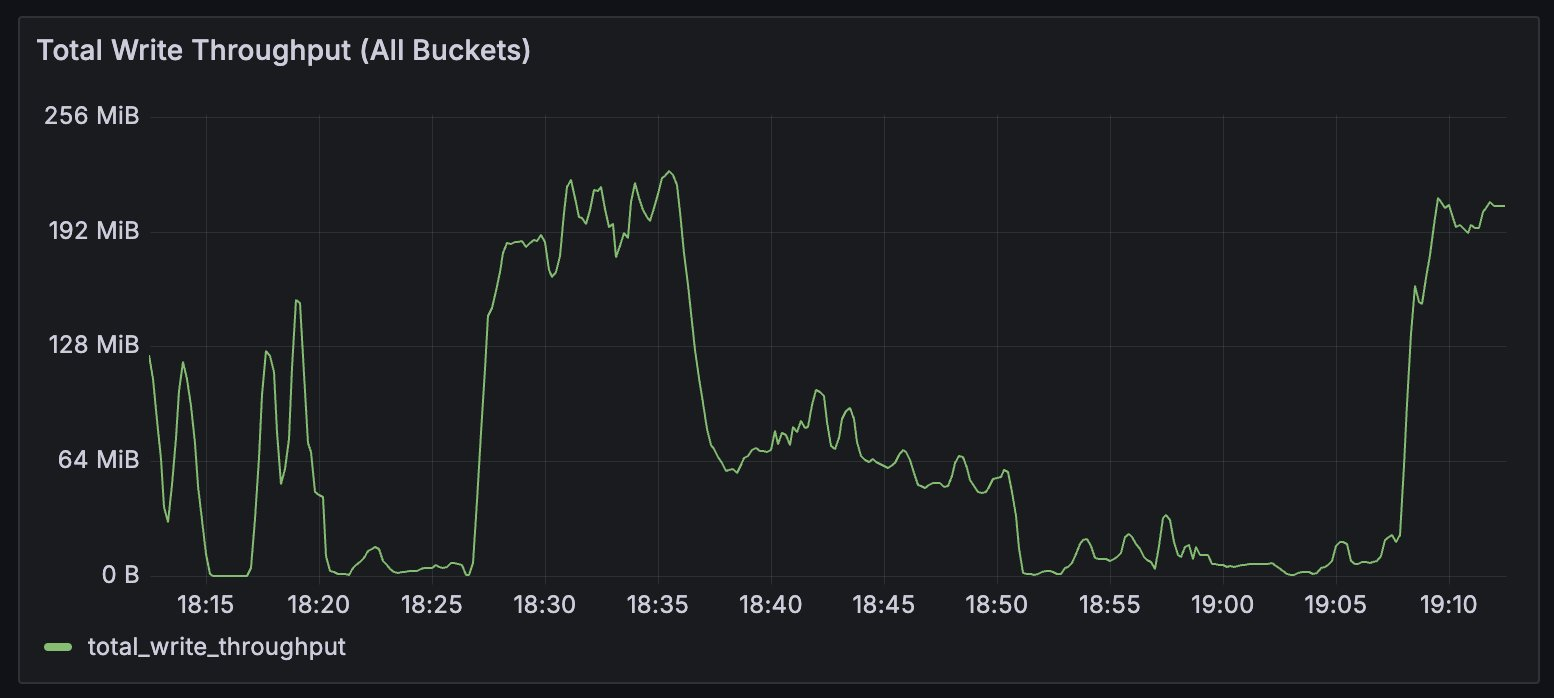
SRE graph scrying test:
I'm backing up a bunch of files to S3, there's moments where the throughput goes down and moments where it goes up.
Assuming no network activity in a way that matters, why would the throughput number be going up and down like this?